Assessment is being drastically impacted by technology, as is much of education. Just like learning is undergoing a sea-change with artificial intelligence, multimedia, gamification, and many more aspects, assessment is likewise being impacted. This post discussed a few ways this is happening.
What is assessment technology?
10 Ways That Assessment Technology Can Improve Exams
Automated Item generation
Newer assessment platforms will include functionality for automated item generation. There are two types: template-based and AI text generators from LLMs like ChatGPT.
Gamification
Low-stakes assessment like formative quizzes in eLearning platforms are ripe for this. Students can earn points, not just in a sense of test scores, but perhaps something like earning coins in a video game, and gaining levels. They might even have an avatar that can be equipped with cool gear that the student can win.
Simulations
 If you want to assess how somebody performs a task, it used to be that you had to fly them in. For example, I used to work on ophthalmic exams where they would fly candidates into a clinic once a year, to do certain tasks while physicians were watching and grading. Now, many professions offer simulations of performance tests.
If you want to assess how somebody performs a task, it used to be that you had to fly them in. For example, I used to work on ophthalmic exams where they would fly candidates into a clinic once a year, to do certain tasks while physicians were watching and grading. Now, many professions offer simulations of performance tests.
Workflow management
Items are the basic building blocks of the assessment. If they are not high quality, everything else is a moot point. There needs to be formal processes in place to develop and review test questions. You should be using item banking software that helps you manage this process.
Linking
Linking and equating refer to the process of statistically determining comparable scores on different forms of an exam, including tracking a scale across years and completely different set of items. If you have multiple test forms or track performance across time, you need this. And IRT provides far superior methodologies.
Automated test assembly
The assembly of test forms – selecting items to match blueprints – can be incredibly laborious. That’s why we have algorithms to do it for you. Check out TestAssembler.
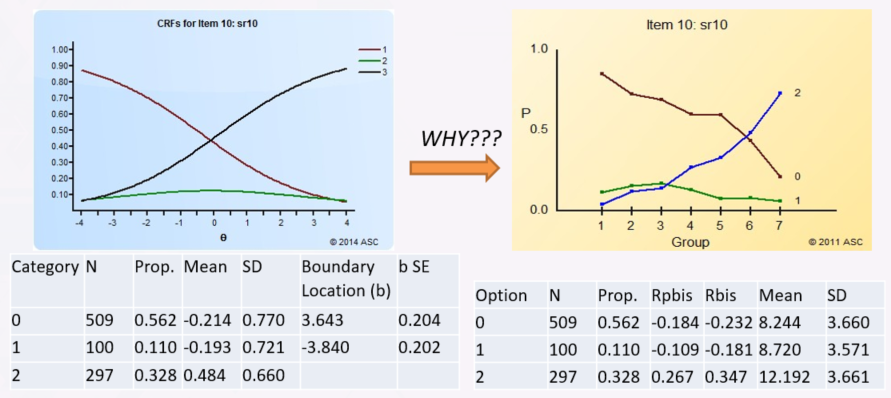
Item/Distractor analysis
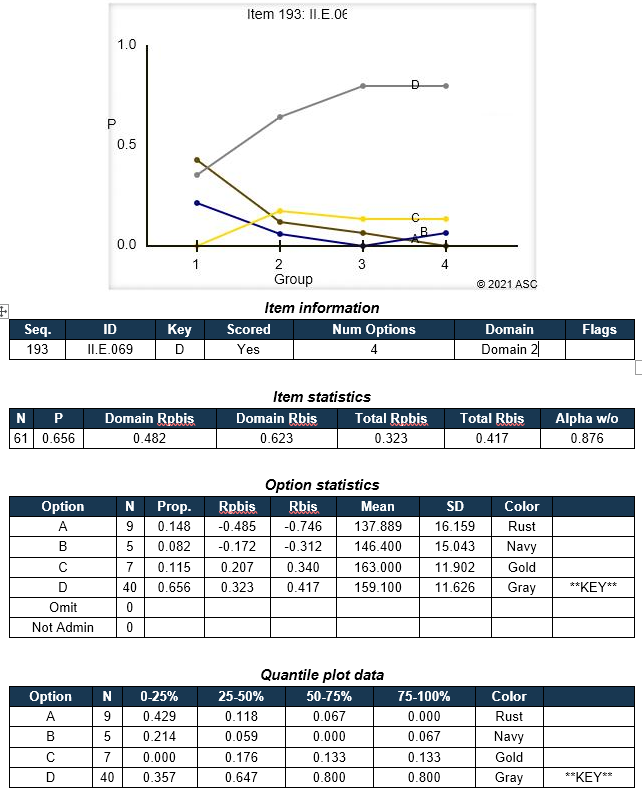 If you are using items with selected responses (including multiple choice, multiple response, and Likert), a distractor/option analysis is essential to determine if those basic building blocks are indeed up to snuff. Our reporting platform in FastTest, as well as software like Iteman and Xcalibre, is designed for this purpose.
If you are using items with selected responses (including multiple choice, multiple response, and Likert), a distractor/option analysis is essential to determine if those basic building blocks are indeed up to snuff. Our reporting platform in FastTest, as well as software like Iteman and Xcalibre, is designed for this purpose.
Item response theory (IRT)
This is the modern paradigm for developing large-scale assessments. Most important exams in the world over the past 40 years have used it, across all areas of assessment: licensure, certification, K12 education, postsecondary education, language, medicine, psychology, pre-employment… the trend is clear. For good reason. It will improve assessment.
Automated essay scoring
This technology is has become more widely available to improve assessment. If your organization scores large volumes of essays, you should probably consider this. Learn more about it here. There was a Kaggle competition on it in the past.
Computerized adaptive testing (CAT)
Tests should be smart. CAT makes them so. Why waste vast amounts of examinee time on items that don’t contribute to a reliable score, and just discourage the examinees? There are many other advantages too.