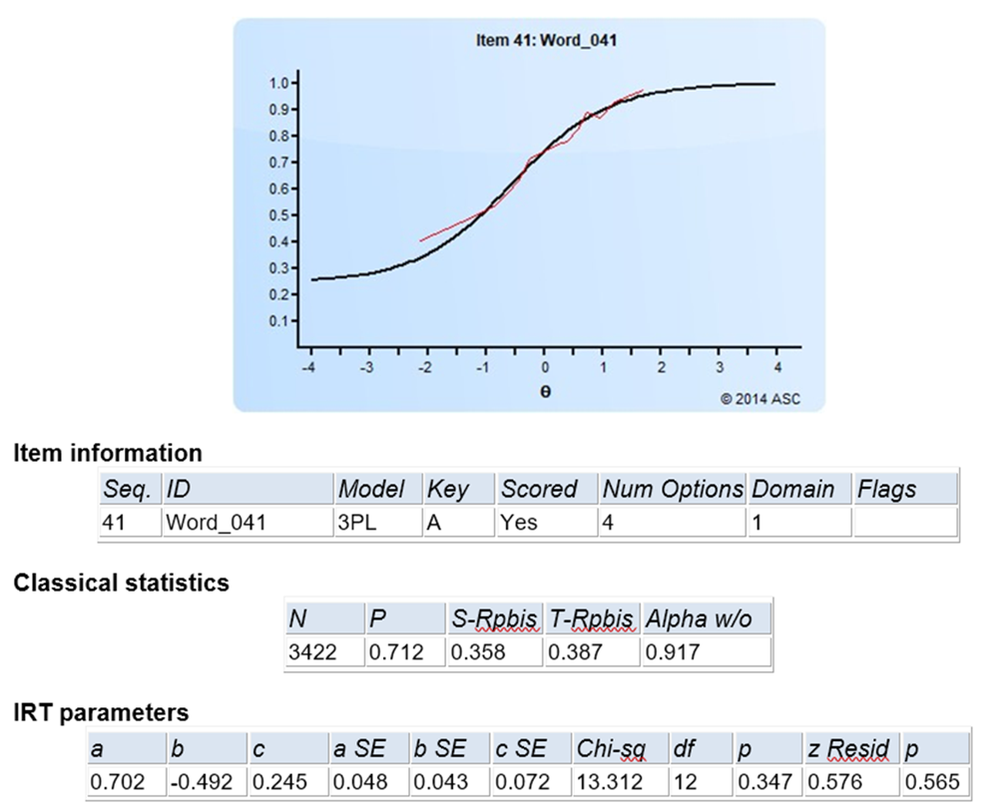
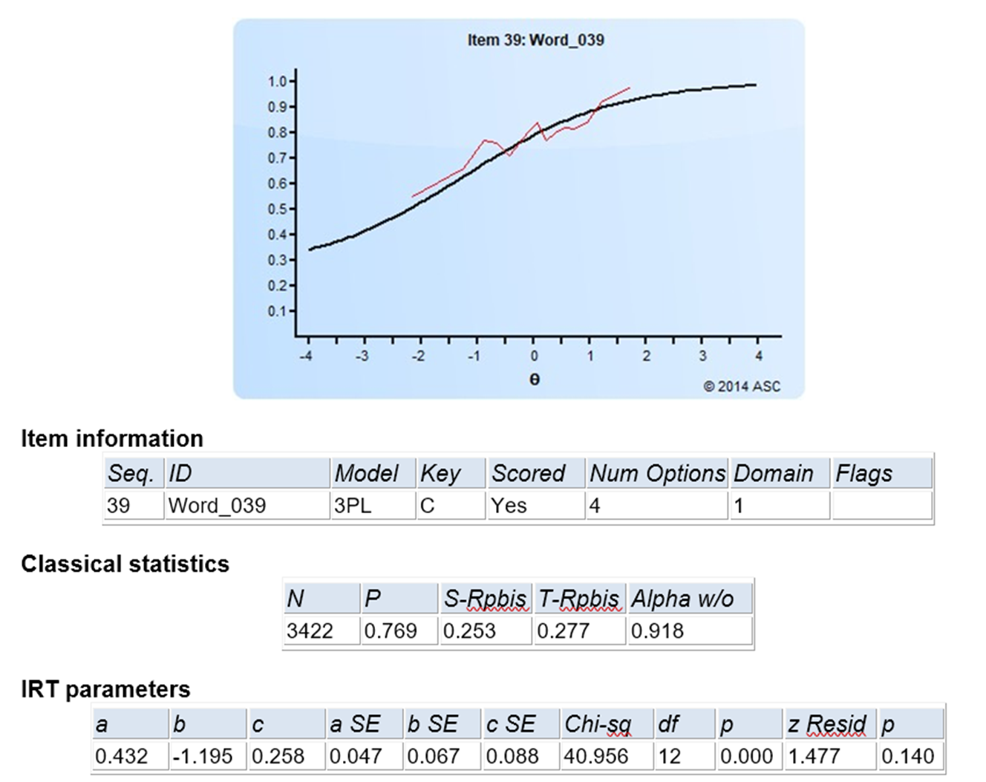
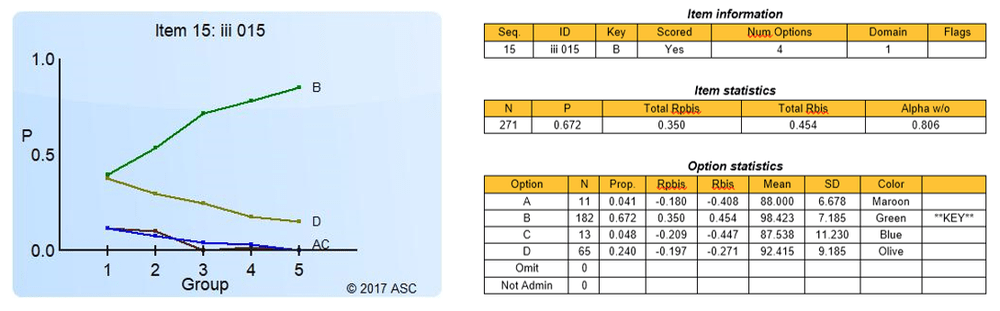
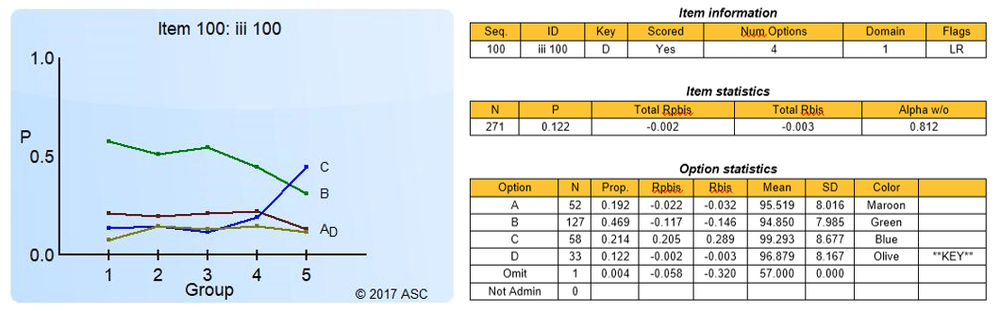
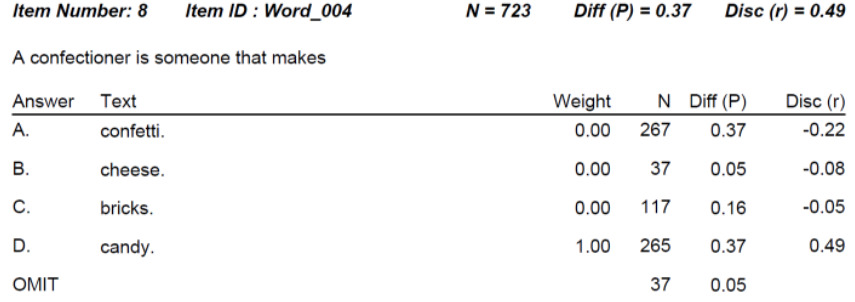
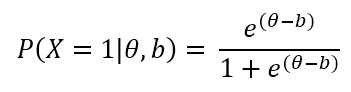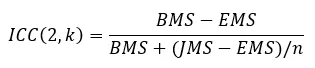The item discrimination parameter a is an index of item performance within the paradigm of item response theory (IRT). There are three item parameters estimated with IRT: the discrimination a, the difficulty b, and the pseudo-guessing parameter c. The item parameter that is utilized in two IRT models, 2PL and 3PL, is the IRT item discrimination parameter a.
Definition of IRT item discrimination
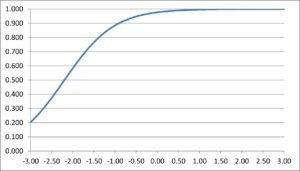
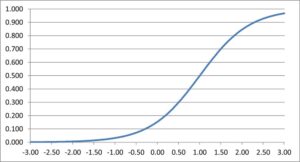
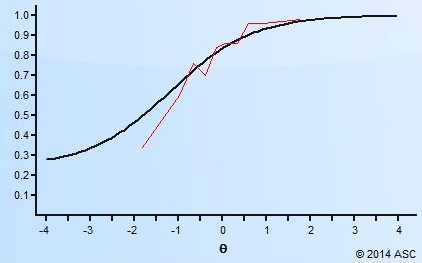
Generally speaking, the item discrimination parameter is a measure of the differential capability of an item. In the analytical aspect, the item discrimination parameter a is a slope of the item response function graph, where the steeper the slope, the stronger the relationship between the ability θ and a correct response, giving a designation of how well a correct response discriminates on the ability of individual examinees along the continuum of the ability scale. A high item discrimination parameter value suggests that the item has a high ability to differentiate examinees. In practice, a high discrimination parameter value means that the probability of a correct response increases more rapidly as the ability θ (latent trait) increases.
In a broad sense, item discrimination parameter a refers to the degree to which a score varies with the examinee ability level θ, as well as the effectiveness of this score to differentiate between examinees with a high ability level and examinees with a low ability level. This property is directly related to the quality of the score as a measure of the latent trait/ability, so it is of central practical importance, particularly for the purpose of item selection.
Application of IRT item discrimination
Theoretically, the scale for the IRT item discrimination ranges from –∞ to +∞ and its value does not exceed 2.0. Thus, the item discrimination parameter ranges between 0.0 and 2.0 in practical use. Some software forces the values to be positive, and will drop items that do not fit this. The item discrimination parameter varies between items; henceforth, item response functions of different items can intersect and have different slopes. The steeper the slope, the higher the item discrimination parameter is, so this item will be able to detect subtle differences in the ability of the examinees.
The ultimate purpose of designing a reliable and valid measure is to be able to map examinees along the continuum of the latent trait. One way to do so is to include into a test the items with the high discrimination capability that add to the precision of the measurement tool and lessen the burden of answering long questionnaires.
However, test developers should be cautious if an item has a negative discrimination because the probability of endorsing a correct response should not decrease as the examinee’s ability increases. Hence, a careful revision of such items should be carried out. In this case, subject matter experts with support from psychometricians would discuss these flagged items and decide what to do next so that they would not worsen the quality of the test.
Sophisticated software provide more accurate evaluation of the item discrimination power because they take into account responses of all examinees rather than just high and low scoring groups which is the case with the item discrimination indices used in classical test theory (CTT). For instance, you could use our software FastTest that has been designed to drive the best testing practices and advanced psychometrics like IRT and computerized adaptive testing (CAT).
Detecting items with higher or lower discrimination
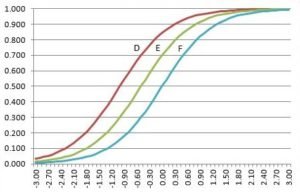
Now let’s do some practice. Look at the five IRF below and check whether you are able to compare the items in terms of their discrimination capability.
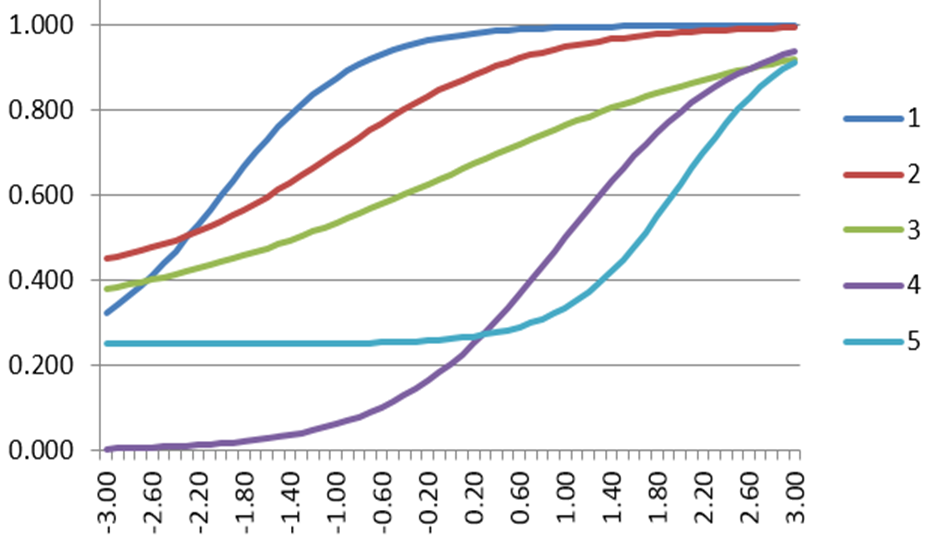
Q1: Which item has the highest discrimination?
A1: Red, with the steepest slope.
Q2: Which item has the lowest discrimination?
A2: Green, with the shallowest slope.