Meta-analysis is a research process of collating data from multiple independent but similar scientific studies in order to identify common trends and findings by means of statistical methods. To put it simply, it is a method where you can accumulate all of your research findings and analyze them statistically. It is often used in psychometrics and industrial-organizational psychology to help validate assessments. Meta-analysis not only serves as a summary of a research question but also provides a quantitative evaluation of the relationship between two variables or the effectiveness of an experiment. It can also work for examining theoretical assumptions that compete with each other.
Background of Meta-Analysis
An American statistician and researcher, Gene Glass, devised the term ‘meta-analysis’ in 1976. He called so the statistical analysis of a large amount of data from individual studies in order to integrate the findings. Medical researchers began employing meta-analysis a few years later. One of the first influential applications of this method was when Elwood and Cochrane used meta-analysis to examine the effect of aspirin on reducing recurrences of heart attacks.

Purpose of Meta-Analysis
In general, meta-analysis is aimed at two things:
- to establish whether a study has an effect and to determine whether it is positive or negative,
- to analyze the results of previously conducted studies to find out common trends.
Performing Meta-Analysis
Even though there could be various ways of conducting meta-analysis depending on the research purpose and field, there are eight major steps:
- Set a research question and propose a hypothesis
- Conduct a systematic review of the relevant studies
- Extract data from the studies to include into the meta-analysis considering sample sizes and data variability measures for intervention and control groups (the control group is under observation whilst the intervention group is under experiment)
- Calculate summary measures, called effect sizes (the difference in average values between intervention and control groups), and standardize
estimates if necessary for making comparisons between the groups
- Choose a meta-analytical method: quantitative (traditional univariate meta-analysis, meta-regression, meta-analytic structural equation modeling) or qualitative
- Pick up the software depending on the complexity of the methods used and the dataset (e.g. templates for Microsoft Excel, Stata, SPSS, SAS, R, Comprehensive Meta-Analysis, RevMan), and code the effect sizes
- Do analyses by employing an appropriate model for comparing effect sizes using fixed effects (assumes that all observations share a common mean effect size) or random effects (assumes heterogeneity and allows for a variation of the true effect sizes across observations)
- Synthesize results and report them
Prior to making any conclusions and reporting results, it would be helpful to use the checklist suggested by DeSimone et al. (2021) to ensure that all crucial aspects of the meta-analysis have been addressed in your study.
Meta-Analysis in Assessment & Psychometrics: Test Validation & Validity Generalization
Due to its versatility, meta-analysis is used in various fields of research, in particular as a test validation strategy in psychology and psychometrics. The most common situation to apply meta-analysis is validating the use of tests in workplace in the field of personnel psychology and pre-employment testing. The classic example of such application is the work done by Schmidt and Hunter (1998) who analyzed 85 years of research on what best predicts job performance. This is one of the most important articles in that topic. It has been recently updated by Sackett et al. (2021) with slightly different results.
How is meta-analysis applied to such a situation? Well, start be reconceptualizing a “sample” as a set of studies, not a set of people. So let’s say we find 100 studies that use pre-employment tests to select examinees by predicting job performance (obviously, there are far more). Because most studies use more than one test, there might be 77 that use a general cognitive ability test, 63 that use a conscientiousness assessment, 24 that use a situational judgment test, etc. We look at the correlation coefficients reported for those first 77 studies and find that the average is 0.51, while the average correlation for conscientiousness is 0.44 and for SJTs is 0.39. You can see how this is extremely useful in a practical sense, as a practitioner that might be tasked with selecting an assessment battery!
Meta-analysis studies will often go further and clean up the results, by tossing studies with poor methodology or skewed samples, and applying corrections for things like range restriction and unreliability. This enhances the validity of the overall results. To see such an example, visit the Sackett et al. (2021) article.
Such research has led to the concept of validity generalization. This suggests that if a test has been validated for many uses, or similar uses, you can consider it validated for your particular use without having to do a validation study. For example, if you are selecting clerical workers and you can see that there are literally hundreds of studies which show that numeracy or quantitative tests will predict job performance, there is no need for you to do ANOTHER study. If challenged, you can just point to the hundreds of studies already done. Obviously, this is a reasonable argument, but you should not take it too far, i.e., generalize too much.
Conclusion
As you might have understood so far, conducting meta-analysis is not a piece of cake. However, it is very efficient when the researcher intends to evaluate effects in diverse participants, set another hypothesis creating a precedence for future research studies, demonstrate statistical significance or surmount the issue of a small sample size in research.
References
Borenstein, M., Hedges, L. V., Higgins, J. P., & Rothstein, H. R. (2021). Introduction to meta-analysis. John Wiley & Sons.
DeSimone, J. A., Brannick, M. T., O’Boyle, E. H., & Ryu, J. W. (2021). Recommendations for reviewing meta-analyses in organizational research. Organizational Research Methods, 24(4), 694-717.
Field, A. P., & Gillett, R. (2010). How to do a meta‐analysis. British Journal of Mathematical and Statistical Psychology, 63(3), 665-694.
Glass, G. V. (1976). Primary, secondary, and meta-analysis of research. Educational researcher, 5(10), 3-8.
Glass, G. V., McGaw, B., & Smith, M. L. (1981). Meta-analysis in social research. Sage Publications.
Gurevitch, J., Koricheva, J., Nakagawa, S., & Stewart, G. (2018). Meta-analysis and the science of research synthesis. Nature, 555(7695), 175-182.
Hansen, C., Steinmetz, H., & Block, J. (2022). How to conduct a meta-analysis in eight steps: A practical guide. Management Review Quarterly, 72(1), 1-19.
Hedges, L. V., & Olkin, I. (1985). Statistical methods for meta-analysis. Academic Press.
Hunter, J. E., Schmidt, F. L., & Jackson, G. B. (1982). Meta-analysis: Cumulating research findings across studies. Sage Publications.
Hunter, J. E., & Schmidt, F. L. (2004). Methods of meta-analysis: Correcting error and bias in research findings. Sage.
Peto, R., & Parish, S. (1980). Aspirin after myocardial infarction. Lancet, 1(8179), 1172-1173.
Sackett, P. R., Zhang, C., Berry, C. M., & Lievens, F. (2021). Revisiting meta-analytic estimates of validity in personnel selection: Addressing systematic overcorrection for restriction of range. Journal of Applied Psychology.
Schmidt, F. L., & Hunter, J. E. (1998). The validity and utility of selection methods in personnel psychology: Practical and theoretical implications of 85 years of research findings. Psychological bulletin, 124(2), 262.




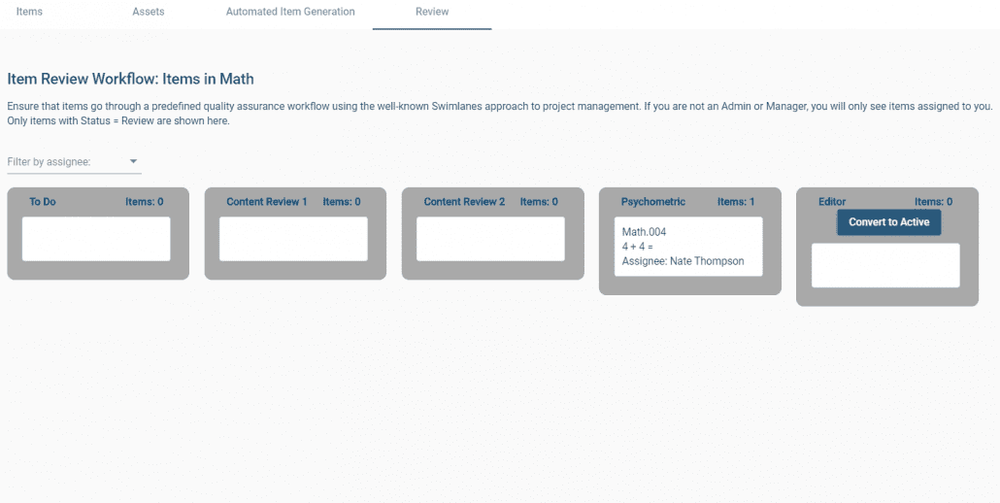

 Specify your stages and how items can move between them
Specify your stages and how items can move between them