A standard setting study is a formal, quantitative process for establishing a performance standard on an exam, such as what score is “proficient” or “passing.” This is typically manifested as a cutscore which is then used for making decisions about people: hire them, pass them, accept them into university, etc. Because it is used for such important decisions, a lot of work goes into standard setting, using methods based on scientific research.
What is NOT standard setting?
In the assessment world, there are actually three uses of the word standard:
- A formal definition of the content that is being tested, such as the Common Core State Standards in the USA.
- A formalized process for delivering exams, as seen in the phrase “standardized testing.”
- A benchmark for performance, like we are discussing here.
For this reason, I prefer the term cutscore study, but the phrase standard setting is used more often.
How is a standard setting study used?
As part of a comprehensive test development cycle, after item authoring, item review, and test form assembly, a cutscore or passing score will often be set to determine what level of performance qualified as “pass” or a similar classification. This cannot be done arbitrarily, such as setting it at 70% because that’s what you saw when you were in school. That is a legal landmine! To be legally defensible and eligible for Accreditation of a Certification Program, it must be done using one of several standard-setting approaches from the psychometric literature. So, if your organization is classifying examinees into Pass/Fail, Hire/NotHire, Basic/Proficient/Advanced, or any other groups, you most likely need a standard setting study. This is NOT limited to certification, although it is often discussed in that pass/fail context.
What are some methods of a standard setting study?
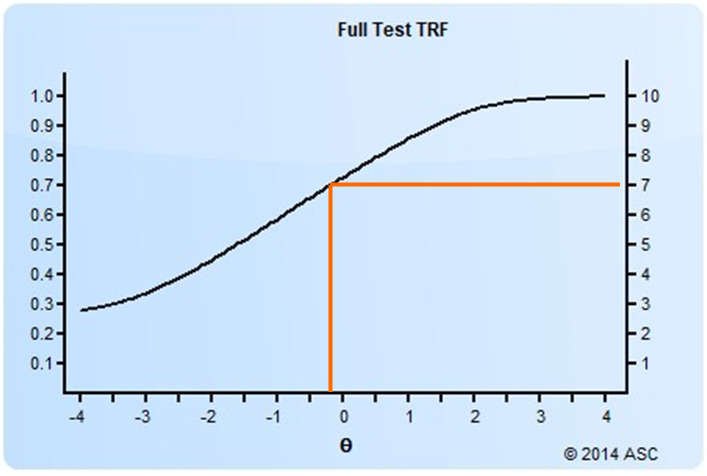
There have been many methods suggested in the scientific literature of psychometrics. They are often delineated into examinee-centered and item-centered approaches. Angoff and Bookmark are designed around evaluating items, while Contrasting Groups and Borderline Groups are designed around evaluating the distributions of actual examinee scores. The Bookmark approach is sort of both types, however, because it uses examinee performance on the items as the object of interest.
Angoff
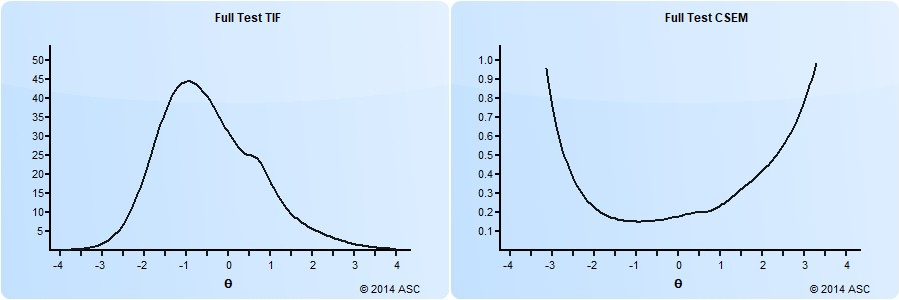
In an Angoff study, a panel of subject matter experts rates each item, estimating the percentage of minimally competent candidates that would answer each item correctly. If we take the average of all raters, this then translates into the average percentage-correct score that the raters expect from a minimally competent candidate – a very compelling argument for a cutscore to pass competent examinees! It is often done in tandem with the Beuk Compromise. The Angoff method does not require actual examinee data, though the Beuk does.
Bookmark
The bookmark method orders the items in a test form in ascending difficulty, and a panel of experts reads through and places a “bookmark” in the book where they think a cutscore should be. Obviously, this requires enough real data to calibrate item difficulty, usually using item response theory, which requires several hundred examinees.
Contrasting Groups
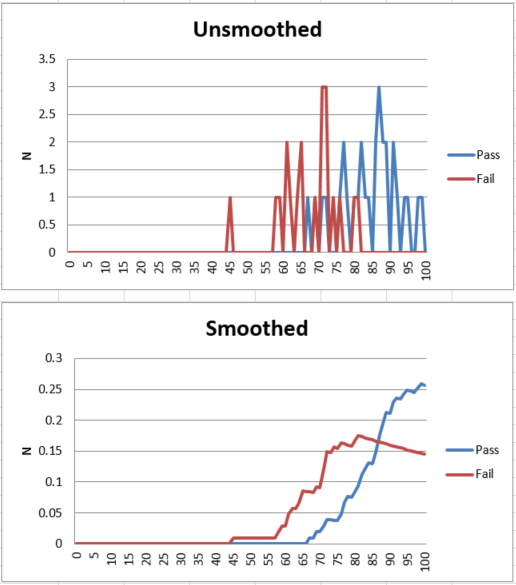
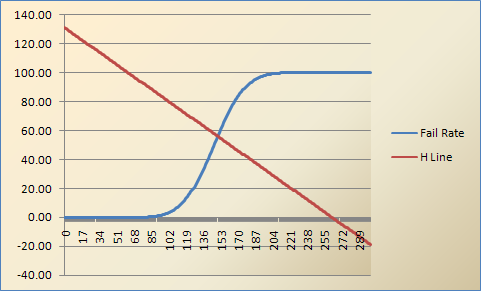
With the contrasting groups approach, candidates are sorted into Pass and Fail groups based on their performance on a different exam or some other unrelated standard. We can then compare the score distributions on our exam for the two separate groups, and pick a cutscore that best differentiates Pass vs Fail on the other standard. An example of this is below. If using data from another exam, a sample of at least 50 candidates is obviously needed, since you are evaluating distributions.
Borderline Group
The Borderline Group method is similar to Contrasting Groups, but a borderline group is defined using alternative information such as biodata, and the scores of the group are evaluated.
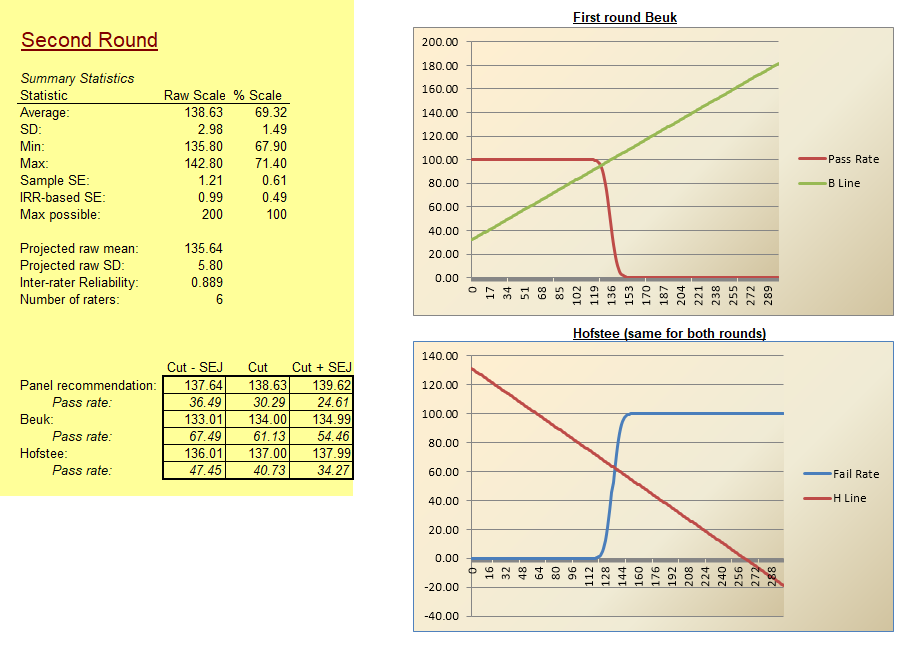
Hofstee
The Hofstee approach is often used as a reality check for the modified-Angoff method, but can be done on its own. It involves only a few estimates from a panel of SMEs.
Ebel
The Ebel approach categorizes items by importance as well as difficulty. It is very old and not used anymore.
How to choose an approach?
There is often no specifically correct answer. In fact, guidelines like NCCA do not lay out which method to use, they just tell you to use an appropriate method.
There are several considerations. Perhaps the most important is whether you have existing data. The Bookmark, Contrasting Groups, and Borderline Group approaches all assume that we have data from a test already delivered, which we can analyze with the perspective of the latent standard. The Angoff and Hofstee approaches, in contrast, can be done before a test is ever delivered. This is arguably less defensible, but is a huge practical advantage.
The choice also depends on whether you can easily recruit a panel of subject matter experts, as that is required for Angoff and Bookmark. The Contrasting Groups method assumes we have a gold standard, which is rare.
How can I implement a standard setting study?
If your organization has an in-house psychometrician, they can usually do this. If, for example, you are a board of experts in a profession but lack experience in psychometrics, you need to hire a firm. We can perform such work for you – contact us to learn more.

 t all teachers had to use the “Chicago Method.” It was pure bunk and based on the fact that students should be doing as much busy work as possible instead of the teachers actually teaching. I think it is because some salesman convinced the department head to make the switch so that they would buy a thousand brand new textbooks. The method makes some decent points (
t all teachers had to use the “Chicago Method.” It was pure bunk and based on the fact that students should be doing as much busy work as possible instead of the teachers actually teaching. I think it is because some salesman convinced the department head to make the switch so that they would buy a thousand brand new textbooks. The method makes some decent points (